This Jupyter notebook hides all input cells on load. To toggle input cell's visibility click on the next link: Show all input
STAR Tracking Optimization Studies¶
In this write-up we discuss potential improvements in the track reconstruction algorithms used by the STAR experiment. The event reconstruction requires a significant amount of CPU resources. Therefore, the objective of this study is to find bottle necks in the code and reduce the overall running time as much as possible.
- Introduction
- Alternative Implementations
- Benchmarking
- Results
- Study of Sti re-fitting routine
joinTwo() - Summary and Outlook
- Open questions and to-do list
- Appendix
Introduction¶
Timing Track Reconstruction Algorithm¶
We start by assessing the performance of the track reconstruction code in the
latest library release [ref needed - ???]. The total time of reconstruction
jobs executed over raw data is measured for three different RHIC Runs completed
in 2017, 2016, and 2015. The timing is done using 300 events with job
options identical to those used in the official reconstruction. The number of
minutes along with the fraction of time spent in the actual reconstruction
algorithm (StiMaker::Make()) reported in Table [#].
Profiling of StiMaker::Make() in libStiMaker.so is done by using the
callgrind tool. We reconstruct 20 events using the same input data and
keeping the Make() calls properly isolated (need a reference to the
corresponding branch in star-sti).
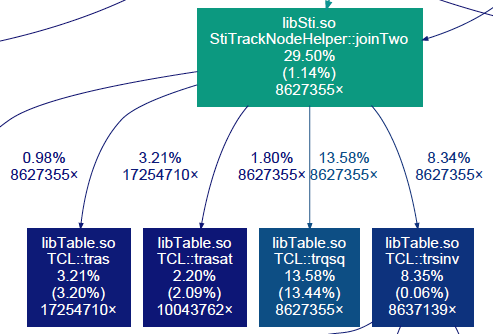
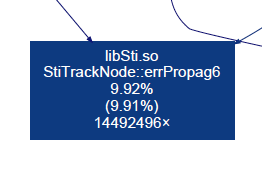
The sampling data collected with callgrind show that the following two
functions use significant franctions of the total time spent in the
StiMaker::Make() routine:
StiTrackNode::errPropag6()~7%StiTrackNodeHelper::joinTwo()~20%
 |
 |
From the reconstruction job log file it appears ~80% of the total time is spent
in StiMaker::Make().
| File | Notes | StiMaker, % (total mins) | joinTwo(), % | errPropag6(), % | ||
|---|---|---|---|---|---|---|
| st_physics_18060106_raw_0000008.daq st_physics_18060107_raw_0000002.daq/3093 | [1](#tbl_note_1) | Sti | 57 (83) | 28 | 9 | |
| StiCA | 63 (97) | 23 | 7 | |||
| st_physics_17072001_raw_3500002.daq | [2](#tbl_note_2) | Sti | 44 (155) | 22 | 7 | |
| StiCA | 46 (177) | 19 | 6.4 | |||
| st_physics_16067017_raw_1000020.daq | [3](#tbl_note_3) | Sti | 34 (67) | 20.4 | 7.1 |
%%html
<p>Toggle next:
<a href='#' onclick='toggleNextInput(this);return false;'>input</a> -
<a href='#' onclick='toggleNextOutput(this);return false;'>output</a>
import plotly
plotly.offline.init_notebook_mode(connected=True)
x = ['18060106', '17072001', '16067017']
time_frac_joinTwo = {
'x': x,
'y': [28, 22, 20.4],
'type': 'bar',
'name': 'joinTwo()'
}
time_frac_errPropag6 = {
'x': x,
'y': [9, 7, 7.1],
'type': 'bar',
'name': 'errPropag6()'
}
data_obj = {
'data': [time_frac_joinTwo, time_frac_errPropag6],
'layout': {
'xaxis': {'type': 'category'},
'barmode': 'stack',
'margin': { 't': 0, 'r': 0, 'b': 20, 'l': 40},
'shapes': [{'type': 'line', 'x0': -0.5, 'y0': 100, 'x1': 2.5, 'y1': 100}]
}
}
plotly.offline.iplot( data_obj, show_link=False, link_text="", filename='components_StiMaker' )
#plotly.offline.plot( data_obj, show_link=False, link_text="", include_plotlyjs=False, output_type='div' )
Notes:
For data reconstruction options see http://www.star.bnl.gov/devcgi/dbProdOptionRetrv.pl
[1] Official reco options for "pp 510GeV run 2017 TOF, TPC dE/dx, MTD, and BeamLine calibration production"
"DbV20170718 pp2017 mtd btof -beamline BEmcChkStat [Sti|StiCA] CorrX OSpaceZ2 OGridLeakFull -hitfilt KeepTpcHit"
get_file_list.pl -keys path,filename,events -cond filename~st_physics_%,runnumber[]18060107-18060107,sanity=1,filetype=online_daq -delim / -limit 10
[2] Official reco options for "auau 200GeV run 2016 st_hlt production for the second period after run number 17062047 with StiCA and without HFT tracking"
"DbV20161001 P2016a [Sti|StiCA] mtd mtdCalib btof picoWrite PicoVtxVpd BEmcChkStat -evout CorrX OSpaceZ2 OGridLeak3D -hitfilt"
get_file_list.pl -keys path,filename,events -cond filename~st_physics_%,runnumber[]17072000-17072047,sanity=1,filetype=online_daq -delim / -limit 10
[3] Official reco options for "pp 200GeV run 2015 production without HFT tracking and with PPV_W mode cut for vertex finding"
"DbV20160418 pp2015c btof mtd mtdCalib pp2pp fmsDat fmsPoint fpsDat BEmcChkStat -evout CorrX OSpaceZ2 OGridLeak3D -hitfilt"
QA :INFO - QAInfo: Done with Event [no. 10/run 18069061/evt. 1467682/Date.Time 20170311.13732/sta 0] Real Time = 758.06 seconds Cpu Time = 757.25 seconds ... QA :INFO - QAInfo:Run is finished at Date/Time 20170428/141636; Total events processed :10 and not completed: 0 QA :INFO - Run completed QA :INFO - ================================================================================= QA :INFO - QAInfo:Chain StBFChain::bfc Ast =7287.85 Cpu =6767.55 ... QA :INFO - QAInfo:Maker StTreeMaker::outputStream Ast = 71.40( 1.0%) Cpu = 65.34( 1.0%) QA :INFO - QAInfo:Maker StEventQAMaker::EventQA Ast = 14.64( 0.2%) Cpu = 12.41( 0.2%) QA :INFO - QAInfo:Maker StMuDstMaker::MuDst Ast = 78.26( 1.1%) Cpu = 71.64( 1.1%) ... QA :INFO - QAInfo:Maker StBTofMatchMaker::btofMatch Ast = 8.98( 0.1%) Cpu = 8.08( 0.1%) QA :INFO - QAInfo:Maker StdEdxY2Maker::dEdxY2 Ast =526.51( 7.2%) Cpu =497.28( 7.3%) QA :INFO - QAInfo:Maker StiMaker::Sti Ast =5705.10(78.3%) Cpu =5356.09(79.1%) QA :INFO - QAInfo:Maker StGenericVertexMaker::GenericVertex Ast = 0.10( 0.0%) Cpu = 0.08( 0.0%) ... QA :INFO - QAInfo:Maker StEmcRawMaker::emcRaw Ast = 27.77( 0.4%) Cpu = 8.98( 0.1%) QA :INFO - QAInfo:Maker StZdcVertexMaker::StZdcVertexMaker Ast = 0.03( 0.0%) Cpu = 0.03( 0.0%) QA :INFO - QAInfo:Maker StMaker::tpcChain Ast =636.53( 8.7%) Cpu =614.18( 9.1%) QA :INFO - QAInfo:Maker StMaker::MtdChain Ast =171.00( 2.3%) Cpu =106.43( 1.6%) ... QA :INFO - QAInfo:Maker St_geant_Maker::geant Ast = 9.48( 0.1%) Cpu = 3.09( 0.0%) ... QA :INFO - QAInfo:Maker St_db_Maker::db Ast = 14.62( 0.2%) Cpu = 10.20( 0.2%) QA :INFO - QAInfo:Maker StIOMaker::inputStream Ast = 1.40( 0.0%) Cpu = 0.72( 0.0%) StAnalysisMaker:INFO - StAnalysisMaker::Finish() Processed 10 events.
Alternative Implementations¶
Currently most matrix operations in Sti are implemented using the old TCL library available in ROOT
In the following tests we use:
- Eigen 3.3.3 (67e894c6cd8f)
- gcc 4.8.2
- SMatrix classes from ROOT 5.34.30
Unless noted all proposed alternative implementations conform to the same original interface. We also make sure that the returned results are identical to the existing Sti functions for the same input.
errPropag6()¶
This function calculates the matrix product B = ASA^T where A, S are 6x6
matrices, S is a symmetric matrix
orig.h - The original version used in Sti
orig_no_branch.h - No
ifstatements to check (non-)zero matrix elements inside the nestedfor-loops. This removes the need for CPU branch predictiontrasat.h - Based on
TCL::trasatsmatrix.h - Vectorized calculation based on
ROOT::Math::SMatrixeigen.h - Vectorized calculation based on
Eigenlibrary
joinTwo()¶
This function calculates the weighted average of two multi-dimensional vectors
$$ \begin{align} M &= \bigl( W_1 + W_2 \bigr)^{-1} \bigl(W_1 X_1 + W_2 X_2 \bigr)\\ W &= \bigl( W_1 + W_2 \bigr)^{-1}\\ \chi^2 &= ...\\ \end{align} $$Various implementations of StiTrackNodeHelper::joinTwo()
orig.h - The original version used in Sti. Assumptions are made about the relative error size of the two measurements. The averaging formula seems to be simplified base on the assumption.
eigen.h - Vectorized implementation based on
Eigenlibrary. The implementation follows the original one inorig.h. This function assumes unpacked input dataeigen_packed.h - Similar to
eigen.hbut unpacks the symmetric input matriceseigen_packed_float.h - Similar to
eigen_packed.h, in addition casts the newly created unpacked data to single precision
Benchmarking¶
We benchmark the above versions of the StiTrackNode::errPropag6() and
StiTrackNodeHelper::joinTwo() functions by calling them in a large number
of iterations.
We focus on vectorized implementation of matrix operations by Eigen and SMatrix. Vectorization in CPUs use large registers to perform simultaneous arithmetic operations on several scalar values.
128 bit registers in SSE: 2 double or 4 single precision (float) scalars
256 bit registers in AVX: 4 double or 8 single precision (float) scalars
512 bit registers in AVX2
Relevant CPU info:
model name : Intel(R) Xeon(R) CPU E5-1607 v2 @ 3.00GHz
flags : ... sse sse2 ... ssse3 ... sse4_1 sse4_2 ... avx ...
How to build¶
To compile the tests do:
cd my-tests
mkdir build && cd build
cmake -D EIGEN_INCLUDE_DIR=~/eigen-67e894c6cd8f/ -D CMAKE_CXX_FLAGS="<cxx_flags>" ../
cmake --build ./ -- VERBOSE=1
A desired target may be specified, e.g.:
cmake --build ./ --target test-StiTrackNode-errPropag6
cmake --build ./ --target test-StiTrackNodeHelper-joinTwo
Currenlty we define the following sets of gcc compiler flags:
<cxx_flags>:
-march=native -O2 -m32 -mno-avx
-march=native -O2 -m64 -mno-avx
-march=native -O2 -m32 -mavx
-march=native -O2 -m64 -mavx
-march=native -O3 -m32 -mno-avx
-march=native -O3 -m64 -mno-avx
-march=native -O2 -m34 -fno-tree-vectorize -D EIGEN_DONT_VECTORIZE
-march=native -O2 -m32 -fno-tree-vectorize -D EIGEN_DONT_VECTORIZE
Another gcc option to try is -ffast-math but it can give significantly
different numerical results.
Running tests for errPropag6()¶
Benchmark one of the StiTrackNode::errPropag6() implementations by running
the test as:
test-StiTrackNode-errPropag6 <test_func_name> <n_iterations> <freq_of_zeros> <verbosity>
with the following values
<test_func_name>: {orig, orig_no_branch, trasat, smatrix, eigen}
<n_iterations>: The number of calls to tested function (default: 1,000,000)
<freq_of_zeros>: A real number f: f = (0, 1] or f <= 0 for realistic simulation
<verbosity>: Verbosity level: v[0-9] , (default: v1)
Running tests for joinTwo()¶
Different implementations of StiTrackNodeHelper::joinTwo() can be
benchmarked similar to StiTrackNode::errPropag6()
test-StiTrackNodeHelper-joinTwo <test_func_name> <n_iterations> <verbosity>
with the following values
<test_func_name>: {orig, eigen_as_orig, eigen}
<n_iterations>: The number of calls to tested function (default: 1,000,000)
<verbosity>: Verbosity level: v[0-9] , (default: v1)
Results¶
errPropag6()¶
Comparison of various benchmark tests with different compiler options.
%%html
<p>Toggle next:
<a href='#' onclick='toggleNextInput(this);return false;'>input</a> -
<a href='#' onclick='toggleNextOutput(this);return false;'>output</a>
import plotly
import plotly_csv
plotly.offline.init_notebook_mode(connected=True)
plotly_data = plotly_csv.make_plotly_data('results_errPropag6.csv')
plotly_obj = {
'data': plotly_data,
'layout': {
'barmode': 'group',
'hovermode': 'closest',
'legend': {
'orientation': 'v',
'x': 0, 'xanchor': 'left',
'y': 1, 'yanchor': 'bottom'
},
'margin': { 't': 0, 'r': 0, 'b': 20, 'l': 40}
}
}
plotly.offline.iplot( plotly_obj, show_link=False, link_text="" )
#plotly.offline.plot( plotly_obj, show_link=False, link_text="", include_plotlyjs=False, output_type='div' )
40% gain in speed when switching from orig to eigen
The plot below shows the time spent in the function for a set of f values
ranging from 0.1 to 0.9. The first point at f = 0 corresponds to the measured
rate for realistic simulation.
joinTwo()¶
Comparison of various benchmark tests with different compiler options.
import plotly
import plotly_csv
plotly.offline.init_notebook_mode(connected=True)
plotly_data = plotly_csv.make_plotly_data('results_joinTwo.csv')
plotly_obj = {
'data': plotly_data,
'layout': {
'barmode': 'group',
'hovermode': 'closest',
'legend': {
'orientation': 'v',
'x': 0, 'xanchor': 'left',
'y': 1, 'yanchor': 'bottom'
},
'margin': { 't': 0, 'r': 0, 'b': 20, 'l': 40}
}
}
plotly.offline.iplot( plotly_obj, show_link=False, link_text="" )
#plotly.offline.plot( plotly_obj, show_link=False, link_text="", include_plotlyjs=False, output_type='div' )
20% gain in speed when switching from orig to eigen_packed
22% gain in speed when switching from orig to eigen_packed_float
For single precision case, need to reconfirm the effect on the output w.r.t. the double precision case
test-eigen¶
This is a test to calculate the inverse of 6x6 matrices using Eigen
$$ C = (A + B)^{-1} $$import plotly
import plotly_csv
plotly.offline.init_notebook_mode(connected=True)
plotly_obj = plotly_csv.make_plotly_obj('results_eigen_inverse.csv')
plotly.offline.iplot( plotly_obj, show_link = False)
#plotly.offline.plot( plotly_obj, show_link = False, include_plotlyjs=False, output_type='div')
6x6 matrices appear to be very small to show the difference between SSE and AVX for single precision
Additional tests with 100x100 and 180x180 (max size constrained by the stack size) matrices showed 15% and 20% respective gains for AVX vs SSE
Study of Sti re-fitting routine joinTwo()¶
In Sti each track candidate (i.e. a track "hypothesis" in a strict mathematical sense) is fit to the hits encountered along the way when track is extrapolated to the next detector volume. The initial track fitting is done in the outside-in direction. In Sti the initial seeding and fitting stages are combined. This procedure described above is referred to as a track fitting stage in Sti.
After the fitting stage Sti enters a re-fitting stage in order to get a more precise measurement of track parameters. The next re-fitting pass is done in the opposite inside-out direction with the already known track parameters in hand.
double StiTrackNodeHelper::joinTwo(int nP1, const double *P1, const double *E1,
int nP2, const double *P2, const double *E2,
double *PJ, double *EJ);
Plots of input distributions and the analysis of joinTwo() calls can be found
at http://nbviewer.jupyter.org/github/plexoos/my-tests/blob/master/sti-profiling/sti_joinTwo_inputs.ipynb
Summary and Outlook¶
Milestone #1
- Benchmark different (vectorized) implementations of top time consuming Sti functions
- Time a typical reconstruction job with new proposed implementations
- Confirm projected gain in speed (0.30 x 0.20 + 0.10 x 0.40) x 0.80 = 0.08
In general, packed symmetric matrices are not good for vectorization. Currently, we don't see much evidence to confirm significant impact of packing/unpacking on the overall performance
In all proposed alternative implementations of existing Sti functions we make sure that the returned results are identical for the same input
64-bit builds seem to give a substantial gain in speed. What exactly prevents us from building 64-bit libraries for STAR reconstruction?
Switching to single precision in vectorized calculations can potentially reduce the processing time by another factor. Which calculations in Sti require double precision?
StiTrackNodeHelper::joinVtx()did not show in the call graph for the tested sample. Is it called byStiMaker::Make()?In these tests we take advantage of the vectorization implemented in Eigen for matrix operations, i.e. the "inner loop". But is there a way or trick to help Eigen to vectorize the "outer loop" over matrix instances even at a cost of data re-packing?
Open questions and to-do list¶
Plug-in tested implementations (e.g. using Eigen) in Sti code and time a real reconstruction job
Produce a call graph for event reconstruction with StiCA
Other functions for potential refactoring are:
StiNodeErrs::zign(),StiNodeErrs::recov()Add implementation of
StiTrackNodeHelper::joinTwo()with SMatrix. This should be similar to the case ofStiTrackNode::errPropag6()Need to sample inputs to
StiTrackNodeHelper::joinTwo()from real events. Again, this is similar to what was done forStiTrackNode::errPropag6()(see Estimating rate of zero matrix elements). Even better if we sample the hit (StiHit) and node (StiNodeErrs) error matrices.Test other compilers? clang, gcc 5/6/7...
Appendix¶
A few useful commands to check supported and enabled options in gcc:
gcc -march=native -Q --help=target
gcc -march=native -E -v - </dev/null 2>&1 | grep cc1
gcc -march=native -mno-avx -dM -E - < /dev/null | egrep "SSE|AVX"
errPropag6()¶
main-errPropag6-vs-trasat-output.cxxcompares the output oferrPropag6()to that ofTCL::trasat(). Both functions calculate the matrix operation given byASA^Twith A, S, and A^T being 6x6 matrices. The test can be compiled at ideone (http://ideone.com/tI1MgY) or by simply doing:g++ -std=c++11 main-errPropag6-vs-trasat-output.cxx
main.cxxprofileserrPropag6()in its original and modified versions. See below for details.
Estimating rate of zero matrix elements¶
For realistic simulation we sampled inputs from 10k calls during reconstruction of a single real event.
Frequency of zeros in F and G matrices by element index
Input raw data file¶
The processing options and the input file used in this test
root4star -l -b -q 'bfc.C(1, 10, "pp2017, btof, mtd, pp2pp, fmsDat, fmsPoint, fpsDat, BEmcChkStat, QAalltrigs, CorrX, OSpaceZ2, OGridLeak3D, -hitfilt", "<input_daq_file>")'
<input_daq_file> = st_physics_18069061_raw_2000021.daq